obb
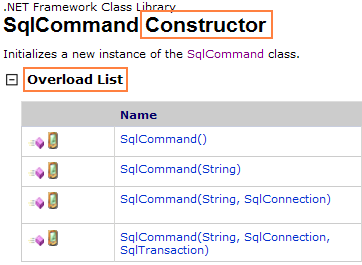
Programing/etc 2012. 5. 22. 18:35 |struct ST_OBB // OBB구조체
{
D3DXVECTOR3 vCenterPos; // 상자 중앙의 좌표
D3DXVECTOR3 vAxisDir[3]; //상자에 평행한 세 축의 단위벡터
float fAxisLen[3]; // 상자의 평행한 세 축의 길이 fAxisLen[n]은 vAxisDir[n]에 각각 대응한다.
};
// ST_OBB 구조체 두개의 포인터를 각각 인자로 받아, 두 OBB의 충돌 여부를 체크하는 함수
// 충돌 시 TRUE리턴, 충돌하지 않으면 FALSE 리턴
BOOL CheckOBBCollision( ST_OBB* Box1, ST_OBB* Box2 )
{
double c[3][3];
double absC[3][3];
double d[3];
double r0, r1, r;
int i;
const double cutoff = 0.999999;
bool existsParallelPair = false;
D3DXVECTOR3 diff = Box1->vCenterPos - Box2->vCenterPos;
for( i = 0 ; i < 3 ; ++i )
{
c[0][i] = D3DXVec3Dot( &Box1->vAxisDir[0], &Box2->vAxisDir[i] );
absC[0][i] = abs( c[0][i] );
if( absC[0][i] > cutoff )
existsParallelPair = true;
}
d[0] = D3DXVec3Dot( &diff, &Box1->vAxisDir[0] );
r = abs( d[0] );
r0 = Box1->fAxisLen[0];
r1 = Box2->fAxisLen[0] * absC[0][0] + Box2->fAxisLen[1] * absC[0][1] + Box2->fAxisLen[2] * absC[0][2];
if( r > r0 + r1 )
return FALSE;
for( i = 0 ; i < 3 ; ++i )
{
c[1][i] = D3DXVec3Dot( &Box1->vAxisDir[1], &Box2->vAxisDir[i] );
absC[1][i] = abs( c[1][i] );
if( absC[1][i] > cutoff )
existsParallelPair = true;
}
d[1] = D3DXVec3Dot( &diff, &Box1->vAxisDir[1] );
r = abs( d[1] );
r0 = Box1->fAxisLen[1];
r1 = Box2->fAxisLen[0] * absC[1][0] + Box2->fAxisLen[1] * absC[1][1] + Box2->fAxisLen[2] * absC[1][2];
if( r > r0 + r1 )
return FALSE;
for( i = 0 ; i < 3 ; ++i )
{
c[2][i] = D3DXVec3Dot( &Box1->vAxisDir[2], &Box2->vAxisDir[i] );
absC[2][i] = abs( c[2][i] );
if( absC[2][i] > cutoff )
existsParallelPair = true;
}
d[2] = D3DXVec3Dot( &diff, &Box1->vAxisDir[2] );
r = abs( d[2] );
r0 = Box1->fAxisLen[2];
r1 = Box2->fAxisLen[0] * absC[2][0] + Box2->fAxisLen[1] * absC[2][1] + Box2->fAxisLen[2] * absC[2][2];
if( r > r0 + r1 )
return FALSE;
r = abs( D3DXVec3Dot( &diff, &Box2->vAxisDir[0] ) );
r0 = Box1->fAxisLen[0] * absC[0][0] + Box1->fAxisLen[1] * absC[1][0] + Box1->fAxisLen[2] * absC[2][0];
r1 = Box2->fAxisLen[0];
if( r > r0 + r1 )
return FALSE;
r = abs( D3DXVec3Dot( &diff, &Box2->vAxisDir[1] ) );
r0 = Box1->fAxisLen[0] * absC[0][1] + Box1->fAxisLen[1] * absC[1][1] + Box1->fAxisLen[2] * absC[2][1];
r1 = Box2->fAxisLen[1];
if( r > r0 + r1 )
return FALSE;
r = abs( D3DXVec3Dot( &diff, &Box2->vAxisDir[2] ) );
r0 = Box1->fAxisLen[0] * absC[0][2] + Box1->fAxisLen[1] * absC[1][2] + Box1->fAxisLen[2] * absC[2][2];
r1 = Box2->fAxisLen[2];
if( r > r0 + r1 )
return FALSE;
if( existsParallelPair == true )
return TRUE;
r = abs( d[2]*c[1][0] - d[1]*c[2][0] );
r0 = Box1->fAxisLen[1] * absC[2][0] + Box1->fAxisLen[2] * absC[1][0];
r1 = Box2->fAxisLen[1] * absC[0][2] + Box2->fAxisLen[2] * absC[0][1];
if( r > r0 + r1 )
return FALSE;
r = abs( d[2]*c[1][1] - d[1]*c[2][1] );
r0 = Box1->fAxisLen[1] * absC[2][1] + Box1->fAxisLen[2] * absC[1][1];
r1 = Box2->fAxisLen[0] * absC[0][2] + Box2->fAxisLen[2] * absC[0][0];
if( r > r0 + r1 )
return FALSE;
r = abs( d[2]*c[1][2] - d[1]*c[2][2] );
r0 = Box1->fAxisLen[1] * absC[2][2] + Box1->fAxisLen[2] * absC[1][2];
r1 = Box2->fAxisLen[0] * absC[0][1] + Box2->fAxisLen[1] * absC[0][0];
if( r > r0 + r1 )
return FALSE;
r = abs( d[0]*c[2][0] - d[2]*c[0][0] );
r0 = Box1->fAxisLen[0] * absC[2][0] + Box1->fAxisLen[2] * absC[0][0];
r1 = Box2->fAxisLen[1] * absC[1][2] + Box2->fAxisLen[2] * absC[1][1];
if( r > r0 + r1 )
return FALSE;
r = abs( d[0]*c[2][1] - d[2]*c[0][1] );
r0 = Box1->fAxisLen[0] * absC[2][1] + Box1->fAxisLen[2] * absC[0][1];
r1 = Box2->fAxisLen[0] * absC[1][2] + Box2->fAxisLen[2] * absC[1][0];
if( r > r0 + r1 )
return FALSE;
r = abs( d[0]*c[2][2] - d[2]*c[0][2] );
r0 = Box1->fAxisLen[0] * absC[2][2] + Box1->fAxisLen[2] * absC[0][2];
r1 = Box2->fAxisLen[0] * absC[1][1] + Box2->fAxisLen[1] * absC[1][0];
if( r > r0 + r1 )
return FALSE;
r = abs( d[1]*c[0][0] - d[0]*c[1][0] );
r0 = Box1->fAxisLen[0] * absC[1][0] + Box1->fAxisLen[1] * absC[0][0];
r1 = Box2->fAxisLen[1] * absC[2][2] + Box2->fAxisLen[2] * absC[2][1];
if( r > r0 + r1 )
return FALSE;
r = abs( d[1]*c[0][1] - d[0]*c[1][1] );
r0 = Box1->fAxisLen[0] * absC[1][1] + Box1->fAxisLen[1] * absC[0][1];
r1 = Box2->fAxisLen[0] * absC[2][2] + Box2->fAxisLen[2] * absC[2][0];
if( r > r0 + r1 )
return FALSE;
r = abs( d[1]*c[0][2] - d[0]*c[1][2] );
r0 = Box1->fAxisLen[0] * absC[1][2] + Box1->fAxisLen[1] * absC[0][2];
r1 = Box2->fAxisLen[0] * absC[2][1] + Box2->fAxisLen[1] * absC[2][0];
if( r > r0 + r1 )
return FALSE;
return TRUE;
}
'Programing > etc' 카테고리의 다른 글
| tinyxml 문제점?? (0) | 2013.01.08 |
|---|---|
| 킹스툴즈 2008 ( 비주얼스튜디오 문서화 ) (0) | 2012.06.12 |
| 소멸자를 가상함수로 해야 하는 이유 (0) | 2012.05.21 |
| xml 장점 단점 (0) | 2012.05.21 |
| 순수, 가상함수 차이 활용 (0) | 2012.05.21 |